
Most ECS-based games run entirely on CPU because writing compute shaders by hand is painful boilerplate that most developers avoid. We want to change that by devising and implementing an approach that will automatically use the GPU to run ECS systems on the GPU when it's worth it.
The Starting Point
The project began from a real codebase — an ECS game using Flecs.NET and raylib in C#.
As entity counts grow, these CPU systems become a bottleneck. The GPU is the best candidate as it can process thousands of entities in parallel, without the sequential overhead of CPU.
The First attempt towards GPU (Manually written):
The first version was hand-written, which requires:
• An EntityData struct mirroring ECS components in GPU.
• A shader implementing IComputeShader with an Execute() body.
• A buffer allocation management, data upload, dispatch, and download.
It worked faster than CPU, but the code was long. Repeating this for every new system is not scalable, which is what led to the need for automation.
The GPU Automation using Decorator
The idea is that if we have a pure function that handles only the computation part of a system, we can decorate it to generate the GPU buffers and shaders automatically. The decorator describes what the inputs and outputs are and the generator does the rest.
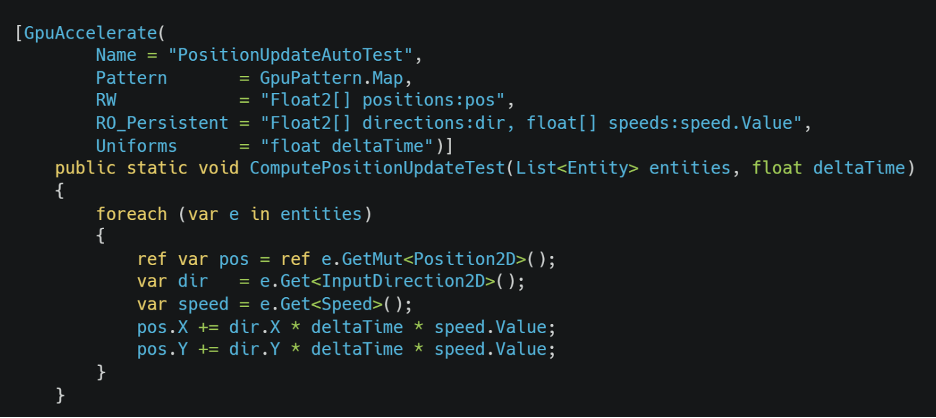
A pre-build Python script scans all .cs files, finds every [GpuAccelerate] method, and generates three files per system into:
• SystemInput.cs — plain struct wrapping CPU arrays
• SystemShader.cs — IComputeShader with transformed Execute()
• SystemKernel.cs — buffer management, Upload(), RunInPlace(), Download()
The generated shader's Execute():

Two Patterns
Two patterns were abstracted to automate the creation of GPU systems for different computational shapes:
Map
One GPU thread per entity, one output per entity. Thread i reads entity i, writes to output slot i. No coordination between threads. Used for position update, gravity, damage.
Pseudocode:
for each entity i in parallel → read my data → compute → write output[i]
AtomicPairs
One GPU thread per entity A, sequential inner loop over all B where B > A. Used for collision detection, queries, interaction checks.
Pseudocode:
for each entity i in parallel → for j > i → if condition → atomic grab slot → write pair
The RO_Persistent Problem
The first generated kernel was slower than CPU.
The approach calls Execute() every frame, which uploads positions, directions, and speeds to the GPU, runs the shader, then downloads the result back to CPU.
The fix was RO_Persistent. Buffers declared with RO_Persistent upload only on the first call; they stay on the GPU permanently. Directions and speeds don't change between frames, so there's no reason to re-upload them.
Combined with RunInPlace() — which runs the shader without any upload or download — the game loop becomes:
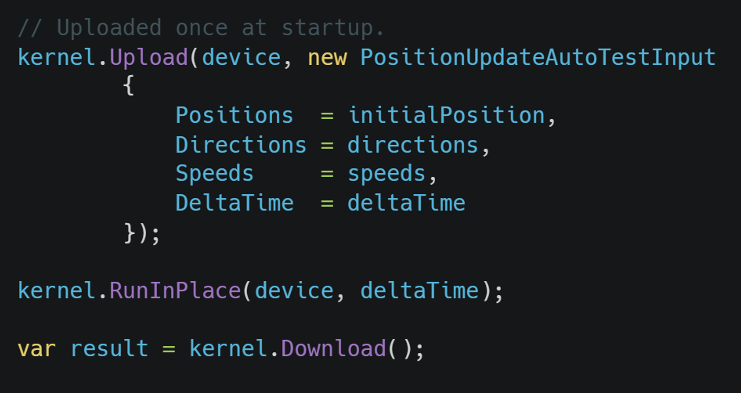
With this pattern, the generated kernel outperforms the hand-written version as positions live on the GPU permanently.
Benchmark Results
Position Update — 10,000 entities
|
Path |
Average per Frame |
Upload |
Time |
Speedup |
|
CPU (ECS) |
11.33
ms |
— |
679.99
ms |
— |
|
Old GPU (manual) |
0.50
ms |
44.90
ms |
30.10
ms |
~22.6× |
|
New GPU (generated) |
0.338
ms |
9.30
ms |
20.26
ms |
~33.1× |
Collision Detection — 5,000 entities
|
Path |
Time |
Speedup |
|
CPU |
10,540
ms |
— |
|
Old GPU (manual) |
1,913
ms |
~5.6× |
|
New GPU (generated) |
84
ms |
~18.7× |
Limitations & Restrictions
• The decorated method must be pure computation.
• RO_Persistent has no invalidation. If entity directions change at runtime, the GPU holds old data.
• Only two patterns.
• The automated script is written in Python. Adds a Python dependency to a C# project.
What's Next
• A more general pattern to cover other systems, which will be semi-automated.
• GPU threshold auto-dispatch — use GpuThreshold to select CPU or GPU at runtime
Conclusion
A decorator turns any pure CPU computation method into a GPU-accelerated system. The developer writes the logic once, then when the project builds, it extracts the math and generates the shader, kernel, and input files automatically.
The system is generic, so any physics system that fits the Map or AtomicPairs pattern can be accelerated by adding one decorator and rebuilding. No shader code, no buffer management, no kernel boilerplate needs to be written by hand.
Although that is demonstrated in the context of the ECS games, the approach is not game-specific. Any domain with pure computation that fits the same patterns — scientific simulation, data processing, machine learning preprocessing — can apply the same decorator-driven generation to accelerate CPU code with minimal effort.
