
AI coding assistants changed the game overnight. A student who once needed hours to copy and rewrite a classmate's submission can now prompt ChatGPT, get a structurally identical solution in seconds, and submit it with a clean conscience – because the variable names are different. Traditional plagiarism checkers compare files as strings. Rename a variable or swap a loop style, and they go blind. We built a tool named CodeSpectra with the help of a four-stage cascade of detection techniques, each designed to catch the tricks the previous stage misses.
"Automation should assist educators – not replace their judgement."
CodeSpectra processes every student submission through a cascade: each stage is tuned for a specific class of plagiarism. Stages do not re-check what the previous stage already caught, so performance stays linear even for large cohorts. Results from all four stages are merged into a single per-student report with a final similarity score and mark penalty.
Stage 1 : Exact-Match Hashing (Type-1)
Every source file is stripped of comments and whitespace, then hashed with MD5. Matching hashes across student submissions flag an exact clone instantly – no further processing needed. This handles the most common case: a student sending their file directly to a classmate. We have applied (1)Comment stripping with multi-language regex patterns,(2) Whitespace normalisation before hashing,(3)O(n) complexity – scales to thousands of submissions. The results are good, having zero false positives for this clone class.
Stage 2: Blind Normalisation + LCS (Type-2)
After exact-match passes, every file goes through two normalisation levels. Pretty-normalisationstrips comments and collapses whitespace while keeping identifier names intact. Blind-normalisation goes further – replacing every non-keyword identifier with a generic token (VAR_0, VAR_1...) so that renamed variables become indistinguishable from originals. Similarity is then computed using Python's SequenceMatcher (Longest Common Subsequence ratio). A raw_sim ≥ 0.95 on pretty-normalised tokens signals Type-1; norm_sim ≥ 0.95 on blind-normalised tokens signals Type-2.
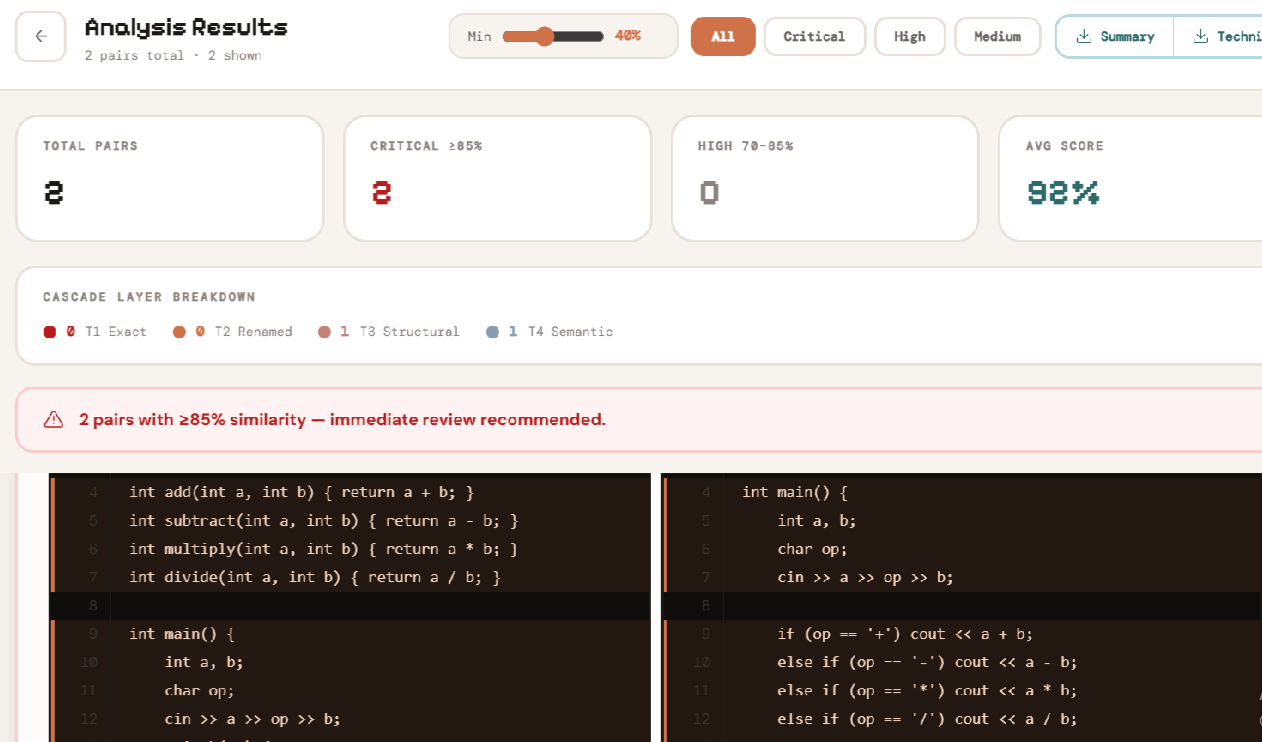
Stage 3: AST Fragments + RandomForest ML (Type-3)
This is where most detectors fail – and where CodeSpectra's main research effort sits. Type-3 clones are fragments that share structure but differ in statements added, removed, or rearranged. A student who rewrites a sorting function, replacing a swap with a temp variable, produces a Type-3 clone.
Stage 4: Semantic Similarity (Type-4)
This is the hardest problem: two programs that do the same thing but look completely different syntactically. A recursive Fibonacci and an iterative Fibonacci are Type-4 clones. An AI-generated solution and a human-written one for the same task may be Type-4 clones. The Type-4 detector uses code embeddings – dense vector representations of program semantics– and computes cosine similarity between them. Pairs with norm_sim < 0.45 (too different for Type-3) but with high embedding similarity are flagged as semantic clones. This is especially relevant in the AI-submission era, where GPT-generated solutions share semantics but not structure.
