
Making a Survivors clone part 1
An introduction to ECS and Data-Oriented Design
Entity Component Systems (ECS) represent a paradigm shift when it comes to developing real-time applications such as games and simulations. By using a data-oriented design approach, ECS has inherently high performance, benefitting from the modern architecture of today's computers. More specifically ECS makes better use of CPU cache thanks to the structure of arrays (SoA) data containment approach, as opposed to traditional OOP that uses arrays of structures (AoS).
Traditional OOP and AoS would have us create an Object with fields; Here we declare an Enemy class that contains basic fields like position, health, and damage.
class Enemy {
Vector2 position;
float health;
float damage;
}
And here is what it might look like in memory:
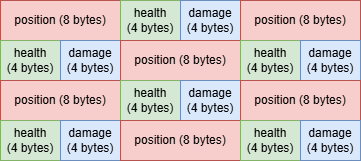
Notice that all the different components of the enemy object follow each other. If we want to access the position component of the enemies, we have no other choice but to load all components of the object from the main memory, causing us to use twice as much memory as we want.
Using a data-oriented approach and SoA, we can create a set of arrays that contain the data fields for said enemies instead of creating an object representing an enemy with its own fields.
Vector2[] enemyPositions;
float[] enemyHeaths;
float[] enemyDamages;
And here is what it might look like in memory:
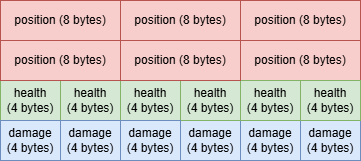
Notice that all the memory allocated to each component type is contiguous, meaning positions are next to positions, healths are next to health and the same for damage. So now if we want to operate on the enemy position component, then we will only deal with position components, leading to less memory usage.
Using SoA has also the benefit of being cache-friendly, with the cache being a blazingly fast memory. In fact, accessing data from the cache is about 25 to 100x faster, depending on hardware, compared to accessing data from main memory, so taking advantage of the cache is essential for better performance. But how does it work? First off, every CPU vendor has their own implementation of cache so I will only give a general rundown of how it works.
Say we were to require access from our array of enemy positions at index 0, the CPU would look in the cache to try and see if it has that data. Since this is the first time we want to access it, there will be a cache miss. The CPU will try to find the data for all cache levels until finally, it finds it in the main memory. The CPU will retrieve the requested data in the array, and will also retrieve the next few elements of the array, and these will all be stored in the cache. Accessing the first element of our array will be quite slow since we have to look into RAM however, for each other iteration the data will be ready on the cache, making it a lot faster.
I want to illustrate this with a small example. Let's say we have a 2d array of bytes of dimensions 2x10.
int rows = 2, cols = 10;
byte[][] arr2d = new byte[rows][];
for(int row = 0; row < rows; row++)
arr2d[row] = new byte[cols];here is what it might look like in memory:

Now I want to increment all the elements of the 2d array, what if I were to tell you that one of these methods is significantly faster than the other, and it is because of cache.
for (int row = 0; row < rows; row++)
for (int col = 0; col < cols; col++)
arr2d[row][col]++;
for (int col = 0; col < cols; col++)
for (int row = 0; row < rows; row++)
arr2d[row][col]++;If you guessed the first implementation, you were right, and here is why.

In the first implementation, we iterate in row-major ordering, meaning that we walk over all the memory locations contiguously.
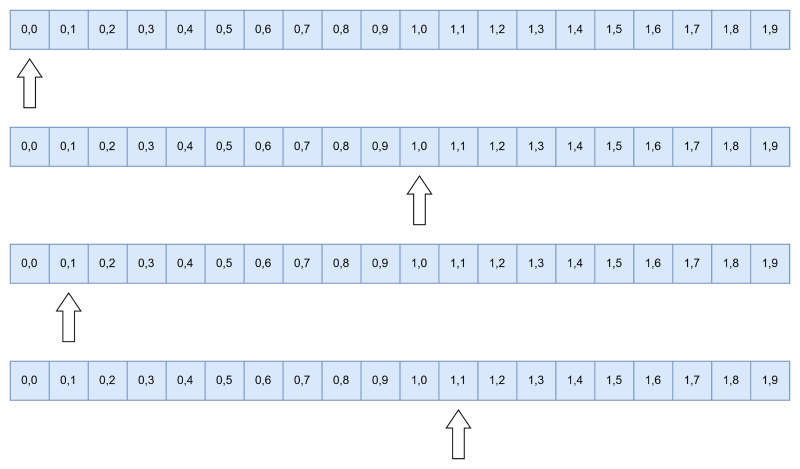
In the second implementation, we iterate in column-major ordering, meaning that we go back and forth in the memory locations.
Going back to cache access, implementation #1 facilitates the preemptive data loading for the cache, leading to faster iteration of the array. When we request array location 0 from the main memory, we also get the next few elements into the cache. In the second implementation, we also get the next few elements, however we switch rows, leading us to check for a memory address that is not next to the previous one. Now the scale of our example is way too small to actually see a meaningful difference, so let's crank it up!
int rows = 9998, cols = 10000;
output:
row-major 47ms
column-major 907ms
19.297873 times fasterWeirdly enough if I set the row count to 9999 instead of 9998, the performance gain is much lower. I think this is due to the cache size of my CPU, it is no longer using the L1 cache and instead using one of the slower ones, however, I'm not entirely sure of what is happening.
int rows = 9999, cols = 10000;
output:
row-major 208ms
column-major 786ms
3.7788463 times fasterBut why am I even talking about all of this? Well, ECS frameworks use cache to their advantage by organizing data in a contiguous way much like we have just demonstrated. The following code block uses the Flecs framework.
// Components
record struct Position (float x, float y);
record struct Damage (float x);
record struct Health (float x);
record struct Renderer (Texture texuture);
void main()
{
// create a containing entity
var world = World.Create();
// entity that has a position
var e1 = world.entity()
.Set<Position>(new(0,0));
// entity that can be rendered
var e2 = world.entity()
.Set<Position>(new(0,0))
.Set<Renderer>(new (new Texture("path")));
// entity that can be rendered and damages
var e3 = world.entity()
.Set<Position>(new(0,0))
.Set<Renderer>(new (new Texture("path")))
.Set<Damage>(new (5));
// entity that can be rendered, damages, and can be damaged
var e4 = world.entity()
.Set<Position>(new(0,0))
.Set<Renderer>(new (new Texture("path")))
.Set<Damage>(new (5))
.Set<Health>(new (5));
}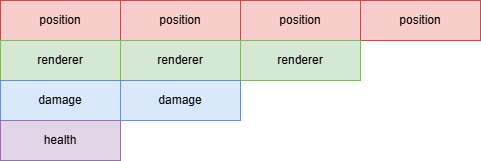
Most ECS frameworks will save the data into arrays of components stored one after the other, a bit like above. There is a lot more to this than I am explaining so consider reading this blog if you are interested in learning more. That's pretty much it for the low-level design of ECS, now let us see how to use this design pattern to create real-time software!
ECS is great, it embraces the composition through components, which are data containers, and is great for decoupling since every system has a unitary task on a set of components. For example, a physics movement system is only responsible for moving components with a velocity and a position, no other logic should be contained there. Here I create a system called "Update Positions" that queries entities with a Position, a Velocity and Speed, and processes the behaviour for each of them.
world.System<Position2D, Velocity, Speed>("Update Positions")
.Each((Iter it, int i, ref Position2D pos, ref Velocity v, ref Speed sp) =>
{
pos.X += v.X * it.DeltaSystemTime() * sp.Value;
pos.Y += v.Y * it.DeltaSystemTime() * sp.Value;
});To be a bit more clear here is a more systematic definition of ECS:
- Entity
- A container for Components. Often represented by an ID. An entity doesn't represent anything on it's own, but is defined by what components it has.
- Component
- Data containers. A set of components define a specific behaviour for a entity e.g., an entity with Damage and without Health can damage others, but cannot be damaged, an entity with Health and Damage can give and receive damage.
- Systems
- A system is a process that acts on a set of components. See the physics system example above.
I think this is enough for technical definitions and we can start applying this to develop a game! :) Throughout this blog post series, I want to develop a Vampire Survivors clone. This seems like a good use of ECS because of the numerous entities present at once, and it is not too complicated a game concept.
In the next instalment, I want to set up a project and start implementing a few systems. I will be using the Flecs framework with C# bindings with the Raylib game library with C# as well.
https://en.wikipedia.org/wiki/Entity_component_system
