
In our previous post, we drew a line between two layers of an urban energy digital twin: the Truth Layer, a relational system of record that protects the structural integrity of a city's data, and a promised Knowledge Layer, a semantic graph that would let that data reason about itself. We closed with a claim left undefended: that connecting the two creates the infrastructure needed to understand cities, compare them, and design better ones.
This post defends that claim. It is the reference architecture for the Ontological Engine — the system that sits atop a Truth Layer API and materialises, on demand, the Brick and RealEstateCore knowledge graphs that make a digital twin queryable, comparable, and interoperable with the wider ecosystem of energy and building tools.
I. The Problem with "Build It All" Ontologies
The naive approach to ontology generation is exhaustive translation: take every entity in the Truth Layer, convert it to RDF, load the entire result into a triple store, and call it the city's digital twin. This approach fails for three structural reasons.
First, staleness. A city's energy systems, meters, and occupancy schedules change continuously. An exhaustively built graph is correct only at the moment of construction; every subsequent API update silently invalidates part of it.
Second, irrelevance at scale. A researcher studying the thermal envelope of a single 1966 building has no use for triples describing ten thousand other buildings. A district planner comparing two parcels needs those two parcels, not the city. Building everything up front optimises for a query pattern almost nobody has.
Third, the compute and storage costs grow with the wrong variable. They grow with the size of the Truth Layer, when they should grow with the size of the question being asked.
The architectural answer is to invert the construction order. Rather than building the graph and then querying it, the engine first queries the Truth Layer and constructs only the graph needed to answer the query. We call this on-demand materialisation: a knowledge graph is not a static export; it is the result of a question.
II. Scope as a First-Class Architectural Concept
Every digital twin platform eventually confronts the question: a twin of what, exactly? A single building? A parcel containing several? An entire district? An arbitrary geographic bounding box drawn by a researcher on a map?
Treating this as an afterthought leads to brittle, special-cased code. We treat it instead as the primary architectural seam, using a strategy pattern: each scope — building, parcel, district, bounding box — is an interchangeable unit that knows only how to fetch raw data for its own boundary. Nothing downstream of it needs to know which scope produced the data it's working with.
This decouples which region of the city is being asked about from how we handle the answer. Adding a new scope — say, "all buildings served by a given transformer," or "all buildings within an emission zone" — means writing one new strategy and registering it. The ontology mapper, the persistence layer, and every API consumer remain untouched.
The unit that travels between these layers is a context object: a typed container holding exactly the raw entities fetched for a given scope, along with a single piece of architectural connective tissue — a unique, addressable identifier for the resulting graph. We mint these as URNs of the form urn:ngci:twin:{scope}:{identifier} — urn:ngci:twin:building:1, urn:ngci:twin:district:1.
III. The System That Makes This Possible
The principle of on-demand, scoped materialisation only matters if there is a concrete system capable of executing it reliably, at two very different scales of request, without asking the caller to know the difference. Picture the system as a chain of calls, each layer asking the next to do one narrow thing on its behalf.
Two entry points sit at the top, and the architecture deliberately treats them as equally first-class: a command-line interface for direct, scriptable use, and a FastAPI service for programmatic and remote access. Both terminate at the same orchestrator — the twin builder — which means a researcher running a one-off query from a terminal and a production service triggering twins on a schedule are exercising identical logic underneath.
The fork beneath FastAPI is the architecture's answer to a problem every twin-building system eventually faces: a single building can be materialised in under a second, while a district can take minutes. Forcing both through the same synchronous request path means either the fast case waits needlessly behind infrastructure built for the slow one, or the slow case times out a caller that was never designed to wait. We resolve this by routing scope, not by routing endpoint: building- and parcel-scoped requests return their result directly; district- and bounding-box-scoped requests are handed to a Redis-backed job queue, executed by Celery workers, and tracked through Flower — but the worker, once it picks up the job, calls into the exact same twin builder the synchronous path uses. The caller never decides which path to take, and neither path duplicates logic.
From the builder, the chain is strictly hierarchical, and each link knows nothing about the links above it. The builder asks a query strategy — one per scope — to fetch what that scope needs. The strategy does not speak HTTP itself; it asks an API client to do that, which calls out to the Truth Layer and returns typed objects rather than raw JSON. Those objects flow back up, scope by scope, until the strategy hands the builder a single populated context — every entity the twin needs, already validated, with no further calls to the Truth Layer required for the rest of the pipeline.
With that context in hand, the builder turns outward in two more directions. It hands the context to the ontology mapper, described in Section VI below, which returns Brick and RealEstateCore triples. It then hands that graph to the graph store, which persists it in Fuseki as a named graph addressed by the URN created at construction time, ready for the SPARQL queries that any downstream tool — an energy model, a carbon accounting platform, a BIM viewer — can issue without ever knowing this chain of calls exists. Figure 1.0 shows an architectural depiction.
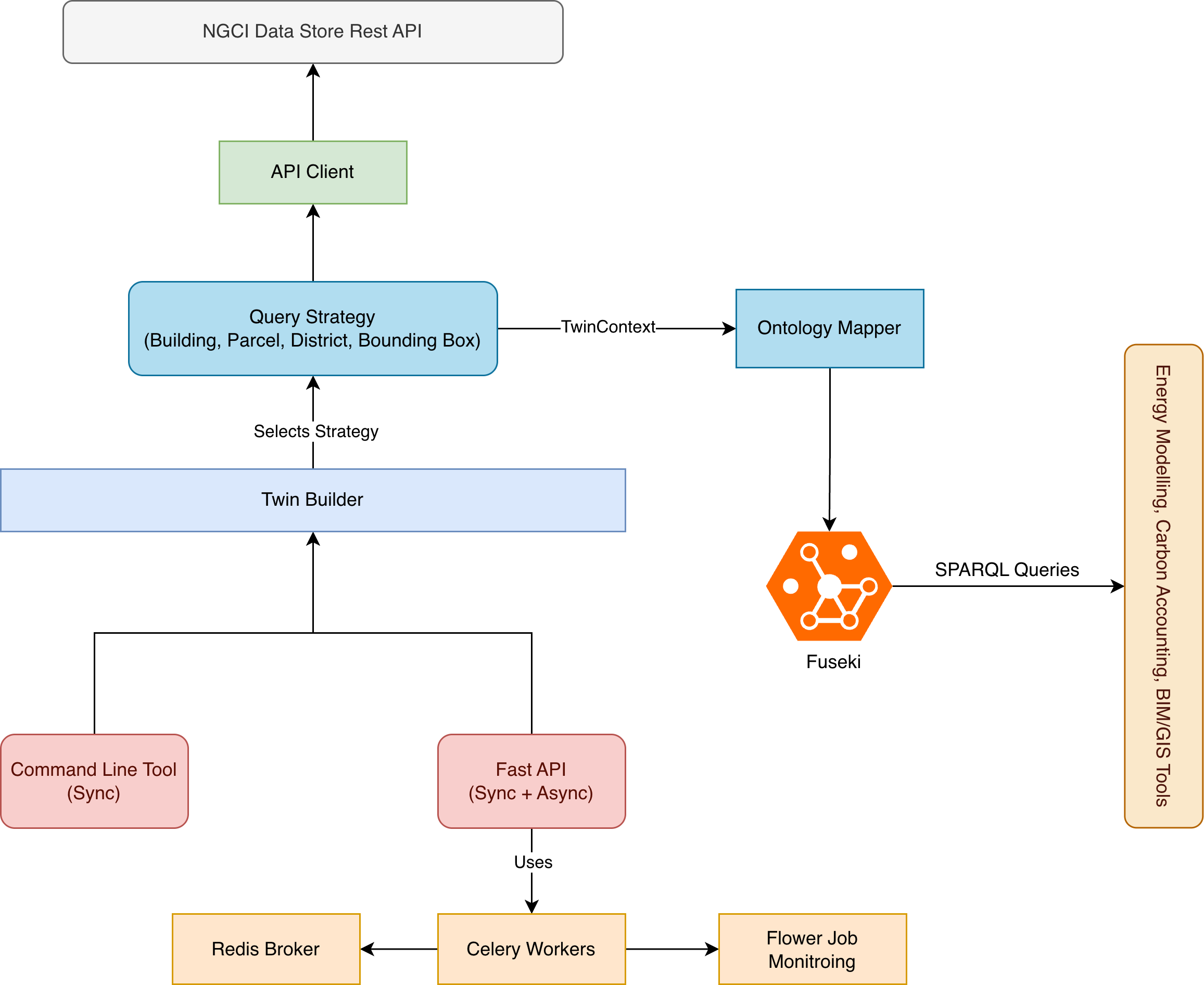
Figur 1.0: Architectural depiction of how on-demand semantic twin is created from the truth layer
IV. A Walkthrough: Materialising One Building
Architecture descriptions risk staying abstract. It is worth walking through what actually happens, end to end, when the smallest possible scope — a single building — is asked to become a twin.
The request can come from either entry point with identical effect. From the command line:
twin-builder build --scope building --id 1
Or from the FastAPI service, for a caller that prefers HTTP:
curl -X POST http://localhost:8000/api/v1/twins/build \
-H "Content-Type: application/json" \
-d '{"scope": "building", "building_id": 1}'Both calls reach the same twin builder, which selects the building-scoped query strategy and invokes it. The strategy's job is narrow by design — it knows how to reach the Truth Layer for exactly one entity type and nothing else:
async def fetch(self) -> TwinContext:
async with BuildingClient() as client:
building = await client.get_building(self._building_id)
return TwinContext(
scope=TwinScope.BUILDING,
graph_uri=build_graph_uri(TwinScope.BUILDING, str(self._building_id)),
buildings=[building],
)The building object returned here is not raw JSON. By the time it reaches the strategy, the API client has already validated it against a typed model — construction year, thermal envelope integrity, embedded meters, embedded HVAC schedules — so everything downstream operates on guaranteed structure, not on hope. This is the context object that returns up the chain described in Section III: a populated TwinContext, addressed by the URN urn:ngci:twin:building:1, with nothing further required from the Truth Layer.
The builder passes that context to the ontology mapper, which produces triples. A small excerpt of what comes out — the building node, one of its meters, and the relationship between them:
ngci:building_1
a rec:Building ;
rdfs:label "Hall Building" ;
ngci:yearOfConstruction 1966 ;
ngci:thermalEnvelopeIntegrity "GOOD" ;
rec:hasPoint ngci:meter_1 .
ngci:meter_1
a brick:Electrical_Meter ;
rdfs:label "SN-99" ;
brick:meters ngci:building_42 ;
ngci:meterType "MAIN_METER" .Two things are worth noticing in those eight lines. The building is rec:Building, never brick:Building — the deprecated class discussed in Section IV. And the meter relationship is expressed in both directions, rec:hasPoint from the building and brick:meters from the meter — a deliberate redundancy that costs two triples and saves every future SPARQL query from needing to know which direction the original author thought to traverse.
That graph is handed to the graph store, which writes it into Fuseki under its URN, and the builder reports back:
{
"graph_uri": "urn:ngci:twin:building:42",
"scope": "building",
"building_count": 1,
"built_at": "2026-06-19T14:02:11Z"
}The twin now exists independently of the request that created it. It can be queried in SPARQL by anything that speaks to the Fuseki endpoint, inspected directly as Turtle, or — and this is the case that matters most for a system meant to outlive any single query — enriched without being rebuilt. If the building's meters report new readings tomorrow, the same building-scoped strategy is invoked again, but this time through the enrichment path: the existing graph is loaded by its URN, the stale meter triples are located and removed, the fresh ones are inserted in their place, and the rest of the graph — geometry, construction year, HVAC schedules — is left untouched because nothing about it changed:
twin-builder enrich --graph-uri urn:ngci:twin:building:1 --type meters --scope building --id 1
One building, one URN, one graph built once and kept current indefinitely thereafter. The next section turns to the discipline that made each of those triples trustworthy in the first place: the vocabulary decisions behind rec:Building, brick:Electrical_Meter, and every other class name that appeared above without explanation.
V. Two Vocabularies, One Graph: Brick and RealEstateCore
Naming the twin is the easy part. Giving its contents meaning is harder, and this is where most digital twin ontologies go wrong: they invent vocabulary rather than adopt it, producing graphs only their creators can interpret.
We anchor the engine in two existing, actively maintained standards rather than one. Brick Schema provides the vocabulary for equipment, sensors, meters, and operational schedules. RealEstateCore (REC) provides the vocabulary for spatial and organisational structure — sites, buildings, and zones. This is not an arbitrary division of labour we invented; it is the division the Brick community itself converged on. As of Brick 1.4, Brick's own location classes — brick:Building, brick:Space among them — are formally deprecated in favour of their REC equivalents. Brick kept what it does best — equipment and points — and ceded spatial semantics to a vocabulary purpose-built for it.
The practical consequence for an architecture like ours is a clean rule, applied consistently across every mapper: if it is a place, it is REC; if it is a thing that senses, measures, or schedules, it is Brick. A building is rec:Building. An occupancy-typed zone within it is rec:OccupancyZone, not the deprecated brick:Space — a zone is defined by what it's used for, which is precisely REC's OccupancyZone concept and precisely not a generic spatial container. A meter is brick:Electrical_Meter. An HVAC schedule is brick:Schedule. Relationships follow the same logic: spatial composition (rec:isPartOf, rec:hasPart) is REC's; metering (brick:meters, brick:isMeteredBy) is Brick's.
No standard, however, anticipates every domain. A building's thermal envelope integrity, its wall-to-window ratio, its district's net-zero target year — these are properties specific to an urban energy digital twin, and neither Brick nor REC defines them. For these, we maintain a third, explicit namespace: ngci:. This is not a failure of the standards; it is the expected and correct boundary of any domain ontology. The discipline lies in keeping that boundary narrow — reaching for Brick or REC first, and only falling back to a custom term when the standard genuinely has no answer.
VI. The Mapping Layer as a Scientific Instrument
Our previous post argued that the mapper between a database entity and its public data transfer object (DTO) is where structural distortion either gets caught or silently passed downstream. The ontology mapper is that same checkpoint, operating one layer up the stack — and the distortions it guards against are semantic, not structural.
A structurally valid translation can still be semantically false. Typing a building's main electrical meter as the generic brick:Meter instead of brick:Electrical_Meter is structurally fine — the triple parses, the graph loads — and semantically wrong: it discards information a downstream energy model needs to select the correct simulation behaviour. Modelling a district parcel as rec:SubBuilding because both "feel like a piece of something larger" is the same error in a different guise: a SubBuilding is a constituent part of one building, like a wing; a parcel is land that may host several independent buildings. The two concepts share a superficial relational shape and almost nothing else.
This is the discipline an ontology mapper enforces. The mapper is not a serialisation step. It is the point at which an engineering data model is checked against a scientific one, which is precisely why we treat its correctness with the same rigour as the DTO mapping it sits above.
VII. Persistence, Not Just Construction: The Graph as a Living Artefact
A graph that exists only in memory for the duration of one query is a report. A digital twin is something else: a persistent, addressable, updatable artefact. This is where on-demand materialisation must be paired with a persistence model that doesn't undermine the very staleness problem it was built to solve.
We persist each materialised twin as a named graph in an RDF triple store, addressed by the URN assigned at construction time. This gives every twin three properties that a flat export cannot: it is independently queryable via SPARQL without touching any other twin in the store; it is independently droppable and rebuildable when the question that produced it needs to be re-asked; and — most importantly — it is independently enrichable.
Enrichment is the architectural answer to staleness. A twin built from a building's structural and geometric data today does not need to be rebuilt from scratch when its meters report new readings tomorrow. The engine instead loads the existing named graph, identifies the triples that describe the entity being refreshed, removes them, and reinserts the current data — a targeted update, not a full reconstruction. The same mechanism that builds a twin for the first time also updates it for the thousandth time.
VIII. Interoperability as the Payoff
This is the section that justifies all the preceding discipline. A bespoke JSON API, however well designed, speaks only to clients written specifically to understand it. Every new consumer — an energy simulation engine, a carbon accounting platform, a BIM viewer — requires a custom adapter that translates field names into its own.
A graph built on Brick and REC requires no such adapter, because the vocabulary was never private to begin with. Any tool that already understands Brick, and a growing ecosystem does, can query our store directly in standard SPARQL and receive triples whose meaning is established by a community standard. This is the architectural payoff of accepting the discipline in Section IV: every hour spent getting a mapping semantically right is an hour of integration work some future, unknown consumer of this twin will never have to do.
This is also where the Truth Layer and Knowledge Layer earn their separate existences. The Truth Layer is bespoke: our city's data model, shaped by our schema decisions. The Knowledge Layer is standard; it is everyone's shared language for talking about buildings and energy. Comparing two cities' digital twins is intractable if each city invents its own ontology. It is tractable and increasingly automatic, the moment both speak Brick and REC.
IX. Toward the Next Layer
What we have described is a structural and behavioural digital twin: buildings, meters, schedules, equipment, correctly typed and correctly related. It does not yet breathe. The next layer of this work brings in what changes by the minute rather than by the season — live sensor enrichment, real-time occupancy, and the district heating and DER systems gestured at but not yet built.
The architecture in this post was deliberately designed to make that extension a matter of writing a new strategy and a new mapper, rather than a redesign. Whether that promise holds is the subject of the next one.
Conclusion: The Graph as the Contract
An ontology engine is easy to dismiss as ceremony, an extra translation step between a perfectly functional API and the people who want to use its data. That dismissal mistakes the cost of standardisation for the cost of incoherence it prevents.
Every decision in this architecture — scoping a twin instead of building one city-sized graph, choosing REC over a deprecated Brick class, removing and reinserting triples instead of rebuilding a graph from scratch — is in service of a single property: that the resulting knowledge graph means the same thing to every system that ever queries it, today or in ten years. A bespoke API is a contract with the clients we wrote it for. A Brick and REC graph is a contract with every client that will ever exist.
The Truth Layer answers the question of what a city's data is. The Ontological Engine ensures that what it is can be understood by anyone who asks.
References
- Brick Schema — Brick Consortium — brickschema.org
- RealEstateCore — REC Consortium — doc.realestatecore.io
- W3C — Resource Description Framework (RDF) — w3.org/RDF
- W3C — SPARQL 1.1 Query Language — w3.org/TR/sparql11-query
- W3C — Web Ontology Language (OWL) — w3.org/OWL
- W3C — Shapes Constraint Language (SHACL) — w3.org/TR/shacl
- Tim Berners-Lee — Linked Data design note — w3.org/DesignIssues/LinkedData
- Wilkinson et al. — The FAIR Guiding Principles for scientific data management and stewardship — Scientific Data, 2016
